Inexplicably, SSIS doesn't natively include a method for generating new GUIDs in the Derived Column Data Flow Transformation.
The get-around is to create a custom Script Component. In SSIS 2008, we have a choice of using Visual Basic or C# to write the script code; I'm going to demonstrate a C# script.
Let's say we have a Data Flow Source and a Data Flow Destination.
(you can click on these pictures to enlarge):
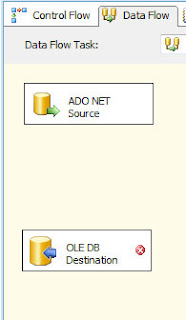
For the sake of this demo, the only difference between the source and the destination is that the destination has a GUID column, with no default constraint which adds its own NEWID() on insert. So we need to generate the GUID in SSIS. The usualy was we'd add a new column worth of data is by using the Derived Column transformation, but as I've mentioned (and you've probably found if you're reading this) there isn't a new GUID option.
So we add a script component.
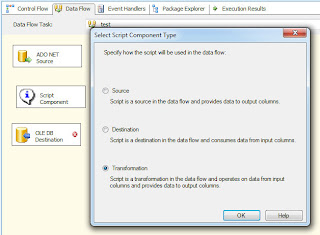
Choose the "Transformation" option, hit OK, and drag the Source's green arrow onto the Script Component.
Double click the script component, then "Inputs and Outputs", then expand Output 0 and Add Column. Call the column whatever you like, but I'm going to call it "SQLNinjaGUID" so you can see how it's referenced in the C# code. Change the data type of the column to unique identifier [DT_GUID].
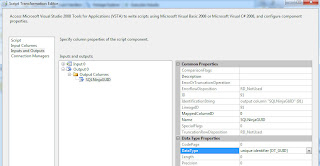
Jump back to the script tab, make sure we're using Microsoft Visual C# 2008 as the ScriptLanguage, Edit Script, and replace ALL of the code with the following.
using System;
using System.Data;
using Microsoft.SqlServer.Dts.Pipeline.Wrapper;
using Microsoft.SqlServer.Dts.Runtime.Wrapper;
[Microsoft.SqlServer.Dts.Pipeline.SSISScriptComponentEntryPointAttribute]
public class ScriptMain : UserComponent
{
public override void Input0_ProcessInputRow(Input0Buffer Row)
{
Row.SQLNinjaGUID = System.Guid.NewGuid();
}
}
Now when you drag the Script Component's green arrow onto your Data Flow Destination, you should see SQLNinjaGUID (or whatever you called your new column) pop up as an available Input Column in the destination's Mapping tab.



